Unicode编码
我们知道计算机是不能直接处理文本的,而是和数字打交道。因此,为了表示文本,就建立了一个字符到数字的映射表,叫做编码。最著名的字符编码就是ASCII了,它使用7-bit来表示应用字母表以及数字和其他字符。这对于英语来说是够用了,但是对于其他语言,这个7-bit就不能满足条件了,因为字符远远超过了7-bit所能表示的最大个数。因此1987年,来自几个大的科技公司的工程师开始合作开发一种致力于能在全世界的所有书写系统中都能通用的字符编码系统,并与1991年10发布了Unicode的1.0.0标准。2018年6月发布了Unicode的11.0版本。这里就不再对Unicode做过多的介绍,值得注意的是,在iOS开发中,常使用的的NSString是基于Unicode-16来开发的,这是因为当时开发这个的时候Unicode标准还是以16bit固定长度来编码,这就导致使用上的一些坑,建议大家阅读下这篇文章:NSString and Unicode。
UCA和CLDR:最常用到的排序标准
介绍完Unicode编码之后,我们就可以来介绍UCA(Unicode Collation Algorithm)和CLDR(Common Locale Data Repository)了,因为苹果的NSString的介绍文档里有这么一句话:1
Localized string comparisons are based on the Unicode Collation Algorithm, as tailored for different languages by CLDR (Common Locale Data Repository). Both are projects of the Unicode Consortium. Unicode is a registered trademark of Unicode, Inc.
说白了,苹果系统的NSString字符串排序是基于UCA的,并且在不同语言下,经过CLDR来裁剪的。
UCA(Unicode Collation Algorithm)
UCA的介绍官方文档介绍在这里:UCA介绍。其中第一句话就写的很清楚,1
Collation is the general term for the process and function of determining the sorting order of strings of characters.
对字符串排序的过程就是Collation,UCA就是Unicode表示的字符串进行排序的规则,制定这个规则的原因是不同语种对字符串的排序规则要求是不一样的,比如,德国、法国和瑞士对相同的字符排序的规则是不一样的,甚至在同一个语言下比如中文,多音字这种在不同组合里,排序的先后顺序也是不一样的。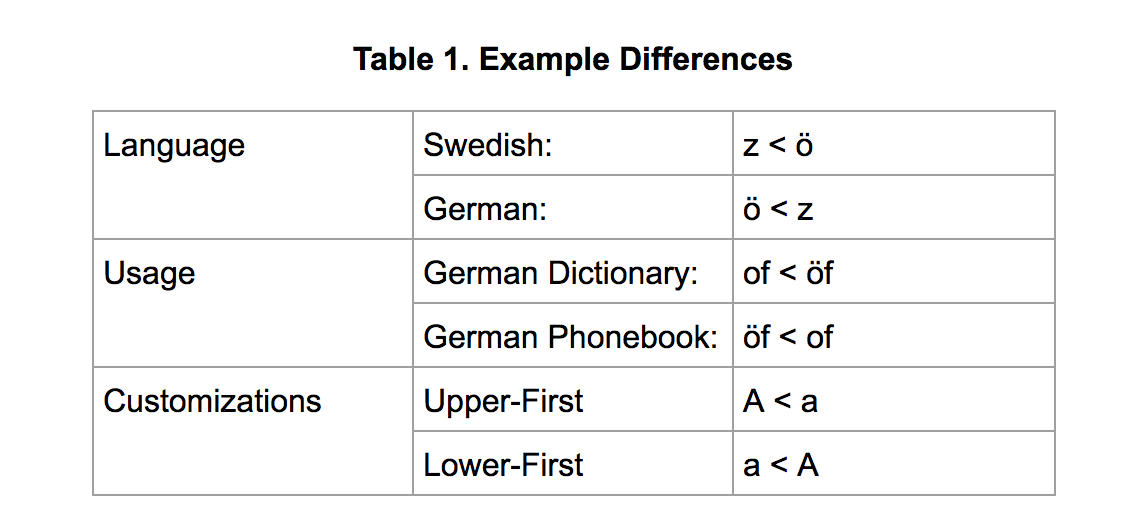
因此可以想象,UCA指定的规则比较复杂。感兴趣的可以读下前面贴的UCA介绍,里面有具体的排序规则介绍。
CLDR(Common Locale Data Repository)
CLDR的官方文档在这里:CLDR介绍。CLDR是一堆语言数据仓库,为软件提供各种世界语言版本提供了基础,目前在使用CLDR的公司有:
- Apple (macOS, iOS, watchOS, tvOS, and several applications; Apple Mobile Device Support and iTunes for Windows; …)
- Google (Web Search, Chrome, Android, Adwords, Google+, Google Maps, Blogger, Google Analytics, …)
- IBM (DB2, Lotus, Websphere, Tivoli, Rational, AIX, i/OS, z/OS,…)
- Microsoft (Windows, Office, Visual Studio, …)
其他公司:
- ABAS Software, Adobe, Amazon (Kindle), Amdocs, Apache, Appian, Argonne National Laboratory, Avaya, Babel (Pocoo library), BAE Systems Geospatial eXploitation Products, BEA, BluePhoenix Solutions, BMC Software, Boost, BroadJump, Business Objects, caris, CERN, Debian Linux, Dell, Eclipse, eBay, EMC Corporation, ESRI, Firebird RDBMS, FreeBSD, Gentoo Linux, GroundWork Open Source, GTK+, Harman/Becker Automotive Systems GmbH, HP, Hyperion, Inktomi, Innodata Isogen, Informatica, Intel, Interlogics, IONA, IXOS, Jikes, jQuery, Library of Congress, Mathworks, Mozilla, Netezza, OpenOffice, Oracle (Solaris, Java), Lawson Software, Leica Geosystems GIS & Mapping LLC, Mandrake Linux, OCLC, Perl, Progress Software, Python, QNX, Rogue Wave, SAP, Shutterstock, SIL, SPSS, Software AG, SuSE, Symantec, Teradata (NCR), ToolAware, Trend Micro, Twitter, Virage, webMethods, Wikimedia Foundation (Wikipedia), Wine, WMS Gaming, XyEnterprise, Yahoo!, Yelp
对于不同区域(local),可以找到不同的数据CLDR,结合UCA对字符串进行排序,就做到了不同语言下的本地化排序。可以去 http://cldr.unicode.org/ 下载最新的CLDR库,后面将会用到里面的一些内容。
字符分类与排序规则
字符分类与Unicode码点值排序
Unicode把所有的字符分为两类:
- common charaters
包括空格,标点,通用符号,货币符号,数字等。 - script charaters
包括拉丁字母,希腊字母,汉字等。
这样经过分类,便于把一类字符统一集中在一起。
通常情况下,我们是通过unicode 的UTF-16码点值逐个进行比较大小的来进行排序的。1
2
3
4
5
6
7
8
9
10NSArray *rawArray = @[@"爱你", @"一生一世",@"㊀", @"上",@"㊤",@"μ",@"язык",@"..",@"123",@"@",@"AA",@"abc",@"abb"];
//1. 默认排序方式
NSArray *defaultedSortedArray = [rawArray sortedArrayUsingComparator:^NSComparisonResult(id _Nonnull obj1, id _Nonnull obj2) {
return [obj1 compare:obj2 options:NSCaseInsensitiveSearch];
}];
__block NSMutableArray *codeUnits = [NSMutableArray array];
[defaultedSortedArray enumerateObjectsUsingBlock:^(NSString* _Nonnull obj, NSUInteger idx, BOOL * _Nonnull stop) {
[codeUnits addObject:@([obj characterAtIndex:0])];
}];
NSLog(@"默认Unicode码点值排序 %@ 对应的各个字符串的首字符码点值是 %@", [defaultedSortedArray descriptionWithLocale:cnLocal], codeUnits);
输出结果是1
2
3
4排序结果
.. 123 @ AA abb abc μ язык ㊀ ㊤ 一生一世 上 爱你
对应的各个字符串的首字符码点值是
46 49 64 65 97 97 956 1103 12928 12964 19968 19978 29233
我们常用的各种字符的码点值范围是:
- 0-9 U+0030 - U0039
- a-z U+0061 - U+007A
- A-Z U+0041 - U+005A
具体可通过:unicode-table查询。
UCA 默认排序
在我们前面下载的文件CLDR库有个/common/uca/allkeys_CLDR.txt文件,它表示我们指定locale为“en”或者说是默认的排序规则。它的格式是1
2
3
40000 ; [.0000.0000.0000] # <NULL>
0001 ; [.0000.0000.0000] # <START OF HEADING>
0002 ; [.0000.0000.0000] # <START OF TEXT>
0003 ; [.0000.0000.0000] # <END OF TEXT>
分号前的值表示码点,分号后中括号里面的值表示UCA算法权重,用.号来区分,Unicode字符就是按照这个规则从上到下排序。1
2
3
4
5NSLocale *enLocale = [[NSLocale alloc] initWithLocaleIdentifier:@"en"];
defaultedSortedArray = [rawArray sortedArrayUsingComparator:^NSComparisonResult(NSString* _Nonnull obj1, NSString* _Nonnull obj2) {
return [obj1 compare:obj2 options:0 range:NSMakeRange(0, obj1.length) locale:enLocale];
}];
NSLog(@"默认排序规则或者指定地区为locale后的排序结果是 %@", [defaultedSortedArray descriptionWithLocale:cnLocal]);
排序结果是1
2默认排序规则或者指定地区为en后的排序结果是
.. (ch (en @ 123 AA abb abc μ язык ㊀ 一生一世 上 ㊤ 爱你
这种排序依次为符号,数字,英文/汉字等script charaters。
CLDR调整后的排序
在下载的CLDR文件中,有个common/bcp47/collation.xml文件,列出了可选的排序方式,有standard,pinyin, stroke(笔画排序)等。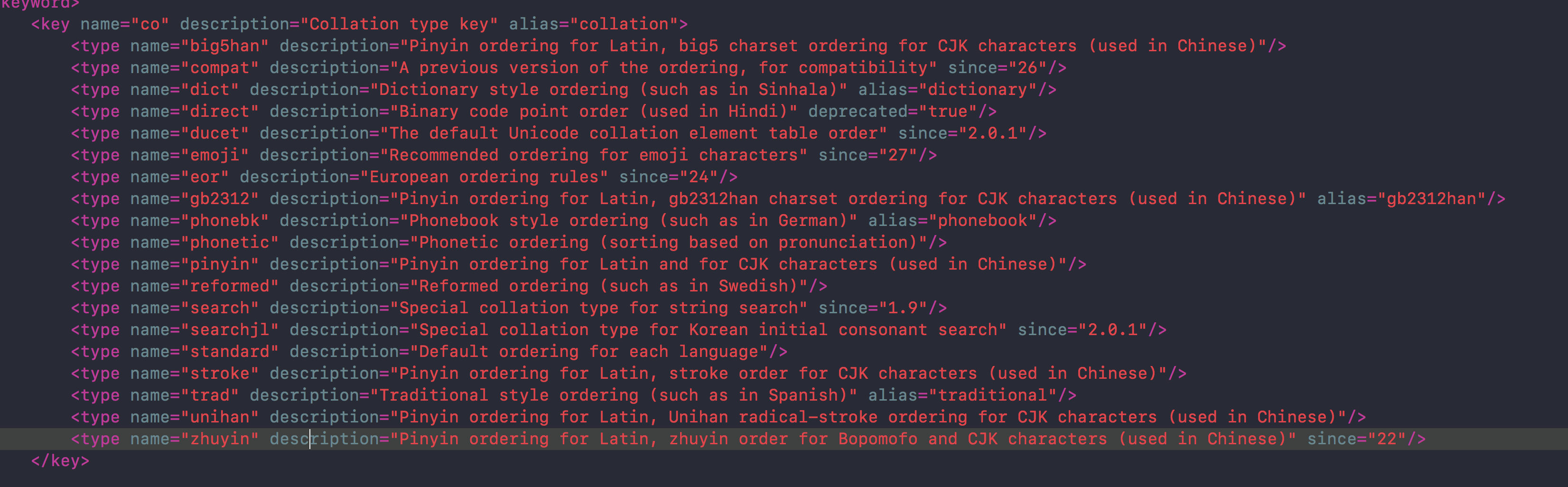
那如何确定各个区域语言下,该使用哪种排序规则呢,我们可以看到common/collation/文件夹下,有很多标记语言LDML文件,这些文件就是表示在不同区域语言下,采用的排序规则。
我们打开zh.xml,这个就是我们简体中文的排序规则,可以看到,里面默认采用的排序是pinyin排序,并且在开头还写了各个声调字母的排序先后顺序。
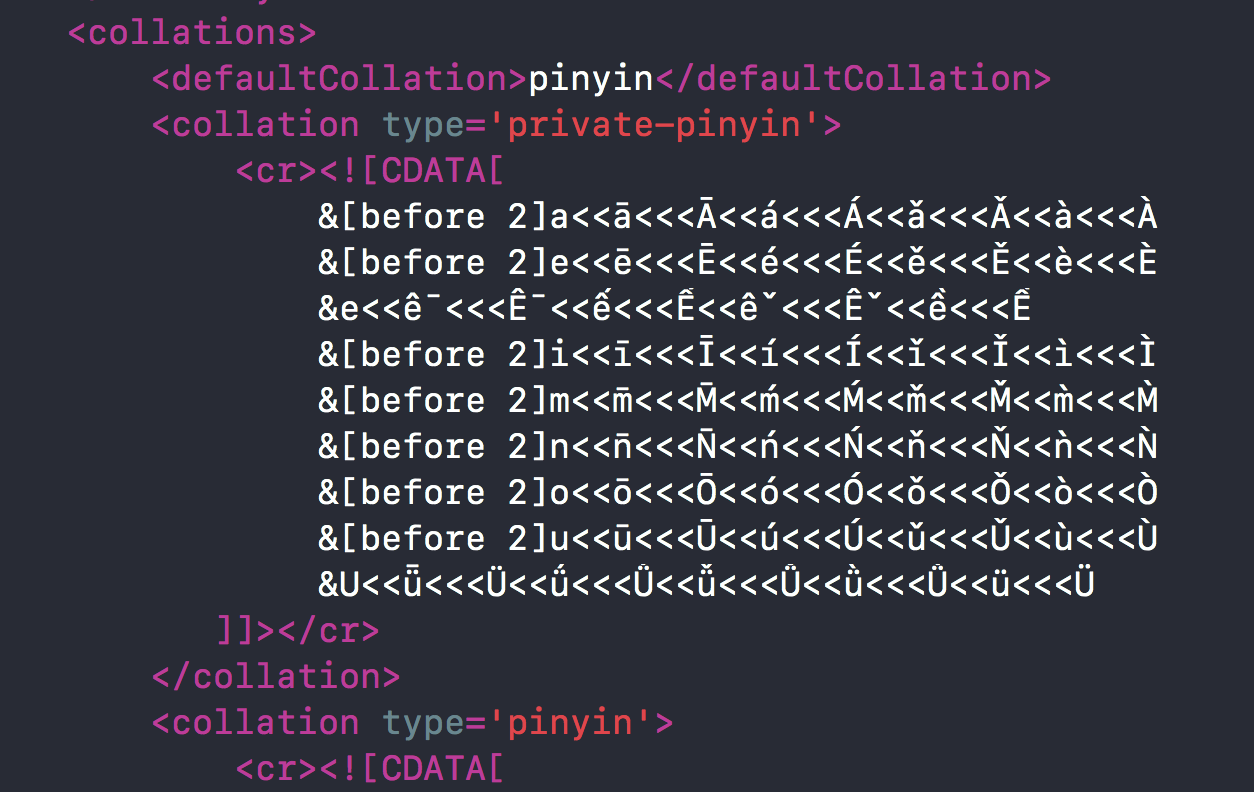
- 首先按照pinyin声调的先后顺序进行排序,即zh.xml底下列出的先后顺序进行排序。
- 如果是在同一行的汉字,则按照笔画由少到多的顺序进行排序。
- 如果还不能区分大小,就按照kRSUnicode (偏旁索引的方式,按照康熙字典的定义)的先后顺序进行排序。
假如我们指定区域为zh_CN,则对于字符串中出现的中文则排在其他语言字符串前面。其他script charater则按照allkeys_CLDR.txt的顺序进行进行排序。值得注意的是,中文由于多音字,在这里不一定能够完全按照我们的习惯排序正确,比如“重逢(chong feng)”就没有第一个拼音chong去排,而是按照zhong来排列的。
1 | 默认排序规则或者指定地区为zh_CN后的排序结果是 |
至此,我们大致讲清楚了几种排序规则。
苹果系统的排序
前面我们已经说了,苹果系统的NSString排序是UCA和CLDR规则的。NSString提供了很多的排序方法,但最终,所有的都是调用了compare:options:range:locale:来进行处理,只是传入的参数不同。可以在NSString.swift 中查看具体的实现。这么多排序方法中,其中之一是localizedStandardCompare:, 这个方法是苹果系统推荐的,在给用户展示的列表数据的名字或者其他字符串进行排序时所使用的方法。我们看到,它的内部实现是1
2
3public func localizedStandardCompare(_ string: String) -> ComparisonResult {
return compare(string, options: [.caseInsensitive, .numeric, .widthInsensitive, .forcedOrdering], range: NSRange(location: 0, length: length), locale: Locale.current._bridgeToObjectiveC())
}
其中用到的四个Options参数是1
2
3
4NSCaseInsensitiveSearch //大小写不敏感
NSNumericSearch //对字符串中出现的数字字符进行数字化的大小比较,比如Foo2.txt < Foo7.txt < Foo25.txt
NSWidthInsensitiveSearch //忽略宽度,按照实际表示的意思来对比,如'a' = UFF41
NSForcedOrderingSearch //强制返回Ascending或者Descending,和NSCaseInsensitiveSearch结合起来就是例如"aaa" > "AAA"
并且指定了当前的区域locale作为参数,这就相当于指定使用CLDR进行排序,如果是在手机上,这个方法的调用和系统当前的区域设置是有很大关系的,这和我们代码中设置locale是一个道理。我们可以这样理解,调用这个方法得到的结果和在iOS Files中文件名选择按照名称排序得到的结果是一样的。在iOS中,当我们的区域设置为中国时,排序顺序就是 标点符号等特殊符号>数字>中文>英文等其他。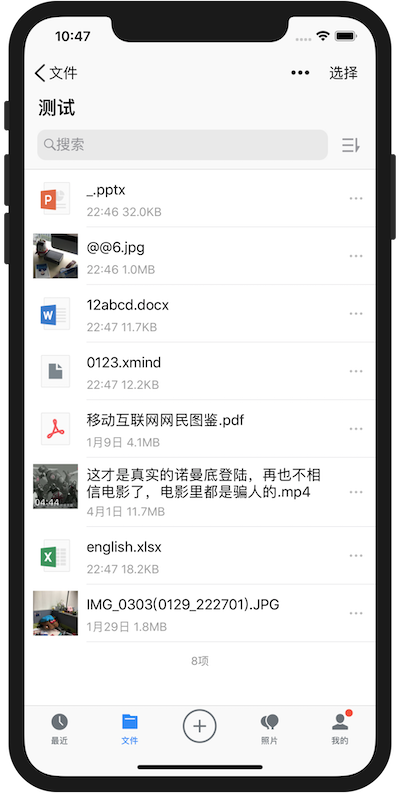
自此,对localizedStandardCompare:的使用,大家应该比较清楚了。
数字的比较
这里单独把数字字符串的比较列出来,是因为一些人对这里比较迷惑。由于localizedStandardCompare:中有使用NSNumericSearch选项,这里简单来说,就是假如目前两个字符串是相等的,两者都出现了数字,则分别从两者种取出这段数字进行数字化来比较大小,按照数字大小排序。为了验证这里的逻辑,我看了下CFString.c中CFStringCompareWithOptionsAndLocale这个方法的实现,这个就是compare实际调用的的比价方法。其中关于数字大小比较的代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36if (numerically && ((0 == strBuf1Len) && (str1Char <= '9') && (str1Char >= '0')) && ((0 == strBuf2Len) && (str2Char <= '9') && (str2Char >= '0'))) { // If both are not ASCII digits, then don't do numerical comparison here
uint64_t intValue1 = 0, intValue2 = 0; // !!! Doesn't work if numbers are > max uint64_t
CFIndex str1NumRangeIndex = str1Index;
CFIndex str2NumRangeIndex = str2Index;
do {
intValue1 = (intValue1 * 10) + (str1Char - '0');
str1Char = CFStringGetCharacterFromInlineBuffer(&inlineBuf1, ++str1Index);
} while ((str1Char <= '9') && (str1Char >= '0'));
do {
intValue2 = intValue2 * 10 + (str2Char - '0');
str2Char = CFStringGetCharacterFromInlineBuffer(&inlineBuf2, ++str2Index);
} while ((str2Char <= '9') && (str2Char >= '0'));
if (intValue1 == intValue2) {
if (forceOrdering && (kCFCompareEqualTo == compareResult) && ((str1Index - str1NumRangeIndex) != (str2Index - str2NumRangeIndex))) {
compareResult = (((str1Index - str1NumRangeIndex) < (str2Index - str2NumRangeIndex)) ? kCFCompareLessThan : kCFCompareGreaterThan);
numericEquivalence = true;
forcedIndex1 = str1NumRangeIndex;
forcedIndex2 = str2NumRangeIndex;
}
continue;
} else if (intValue1 < intValue2) {
if (freeLocale && locale) {
CFRelease(locale);
}
return kCFCompareLessThan;
} else {
if (freeLocale && locale) {
CFRelease(locale);
}
return kCFCompareGreaterThan;
}
}
这段代码的含义就是,如果两个字符串都是以数字开始(也可能是字符串前面都相等,当前从数字部分开始比较),则取出两个字符串的数字,按照数字大小进行对比。如果数字能够比较出大小,则直接返回两个字符串的大小关系,不再对后面的字符串进行对比。比如“0123aaa” 和“1bbbbbbbbb”,就直接返回“0123aaa”大于“1bbbbbbbbb”。当然,这里取出的数字可能超出了uint64_t表示的最大值,但是这种概率很低,在我们的名称排序中,很难遇到这么长的数字进行比较的。明白这个规则后,大家对字符串中出现的数字在进行排序时应该比较理解了。下面的名字排序是对着的。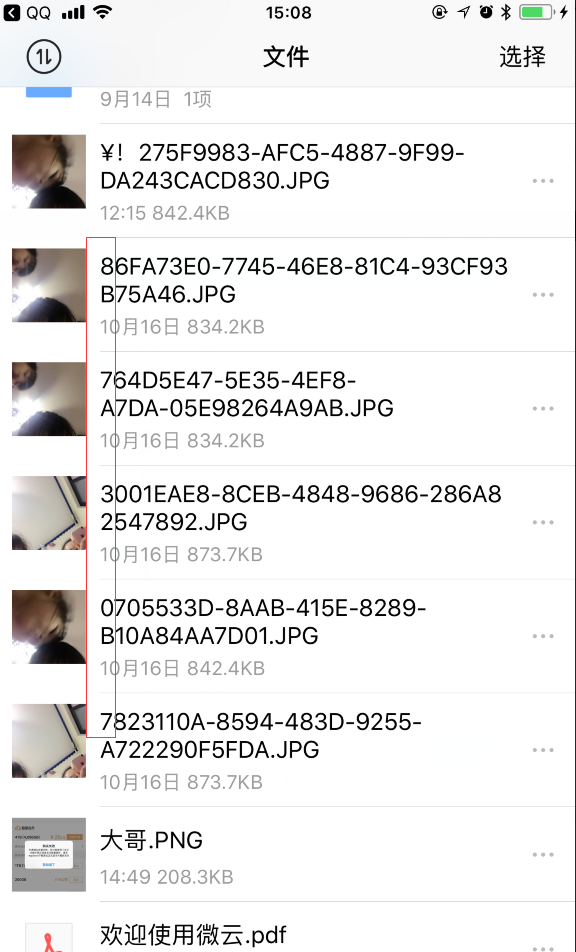
综述
本文主要讲述由localizedStandardCompare:这个苹果系统方法所引发的对排序规则的深入研究,简单来说,设置中选择区域为中国时,排序顺序为 标点符号等特殊符号>数字>中文>英文等其他。中文本身是按照pinyin排序的,只是由于多音字的关系,不能够做到100%按照中文习惯来排序,会有些无法正确排序的问题,但大体已经符合我们的习惯了。
参考
https://zh.wikipedia.org/wiki/Unicode
https://developer.apple.com/library/archive/documentation/CoreFoundation/Conceptual/CFStrings/Articles/UnicodeBasis.html
https://www.objc.io/issues/9-strings/unicode/
http://unicode.org/reports/tr10/
https://www.cnblogs.com/huahuahu/p/Unicode-zi-fu-chuan-pai-xu-gui-ze-yi-ru-he-que-din.html
https://raw.githubusercontent.com/larvit/larvitgeodata/master/cldrData/common/uca/allkeys_CLDR.txt
http://cldr.unicode.org/